Abstract
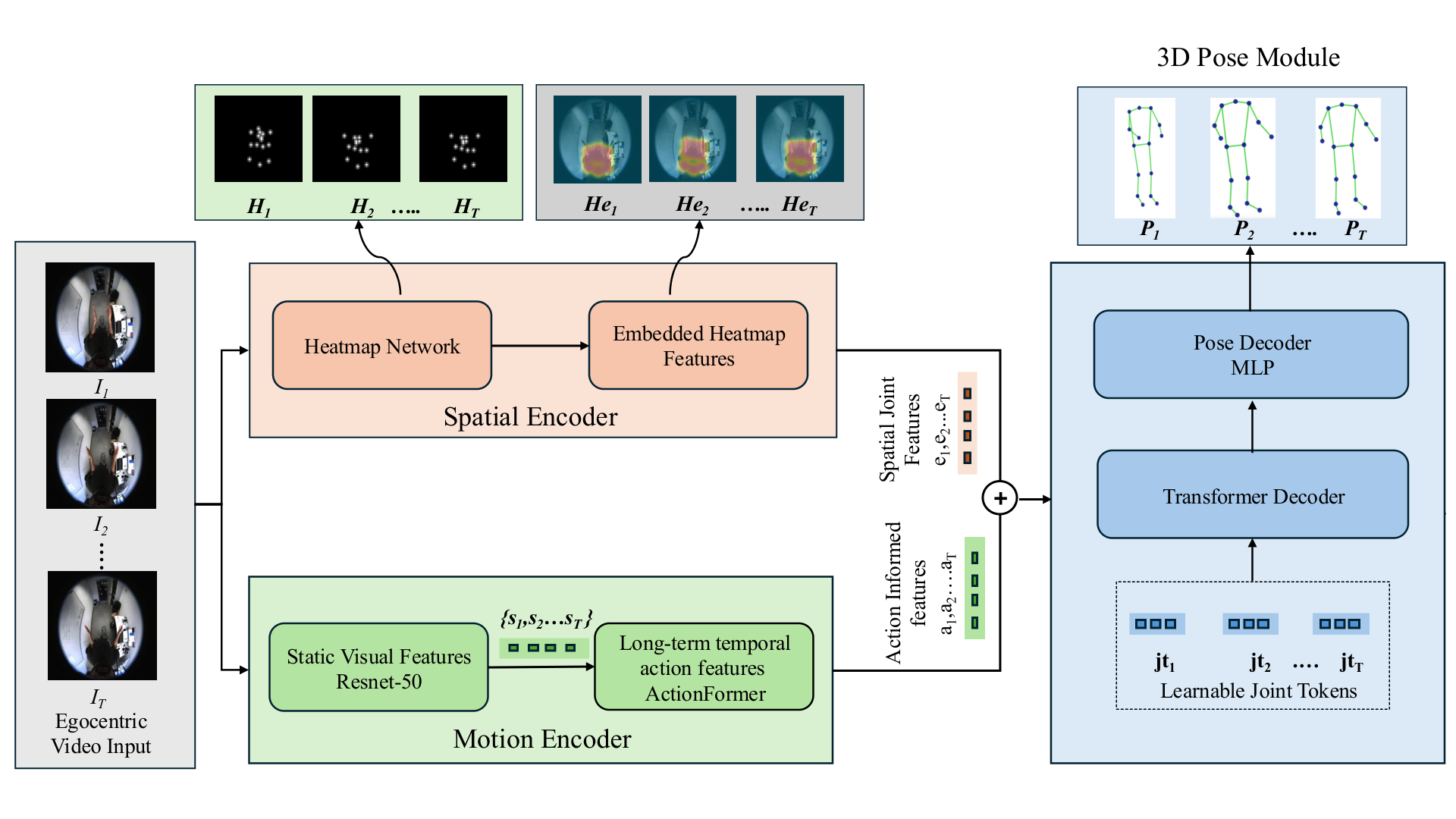
Egocentric 3D human pose estimation remains challenging due to severe perspective distortion, limited body visibility, and complex camera motion inherent in first-person viewpoints. Existing methods typically rely on single-frame analysis or limited temporal fusion, which fails to effectively leverage the rich motion context available in egocentric videos. We introduce AG-EgoPose, a dual-stream framework that integrates short- and long-range motion context with fine-grained spatial cues for robust pose estimation from fisheye camera input. Our framework features two parallel streams: a spatial stream uses a weight-sharing ResNet-18 encoder–decoder to generate 2D joint heatmaps and corresponding joint-specific spatial feature tokens, while a temporal stream uses a ResNet-50 backbone with an action-recognition module to capture motion dynamics. These complementary representations are fused in a transformer decoder with learnable joint tokens, enabling joint-level integration of spatial and temporal evidence. Experiments on real-world datasets demonstrate strong performance in both quantitative and qualitative evaluations.
Key Contributions
- Dual-stream design that jointly models fine-grained spatial cues (heatmaps/tokens) and long-term motion dynamics for egocentric pose.
- Action-guided temporal stream that leverages an action recognition backbone to encode motion context beyond short clips.
- Transformer decoder fusion with learnable joint tokens for joint-wise integration of spatial and temporal evidence.
- Training with multi-term supervision (3D pose, heatmaps, and kinematic consistency) to encourage anatomically plausible predictions.
Model Architecture
Method
Encodes each egocentric frame with a lightweight CNN to extract fine-grained spatial features that correlate with body configuration.
Models longer-term motion context via an action-aware backbone, providing temporally coherent cues for pose disambiguation.
Fuses spatial and temporal representations using a transformer decoder with learnable joint tokens for joint-wise integration.
Predicts per-frame 3D joints from fused tokens, optimized with standard 3D pose objectives on egocentric benchmarks.
Resources
BibTeX
@inproceedings{azam_agegopose_2026,
title = {AG-EgoPose: Action-Guided Egocentric 3D Human Pose Estimation},
author = {Azam, Md Mushfiqur and Desai, Kevin},
booktitle = {Under Review},
year = {2026}
}Acknowledgement
This material is partially supported by the National Science Foundation under Grants 2316240 and 2403411.