Abstract
Rendering high-fidelity human avatars from monocular video with accurate surface details is crucial for applications in virtual reality, digital entertainment, and telepresence. While neural radiance field (NeRF) based models have shown promise in capturing human body representations, they often fail to render fine-grained details, such as cloth wrinkles and facial contours, resulting in noticeable artifacts outside the human body that undermine realism. Existing approaches lack the capability to achieve both detailed texture representation and seamless surface geometry. To address these limitations, we propose TE-NeRF, an enhanced framework that integrates Triplane features to improve detail accuracy and reduce artifacts. By associating Triplane-based features with each SMPL vertex and processing them through a density MLP, our method achieves precise representation of texture and geometry. An adaptive weight blending mechanism dynamically combines vertex-specific and ray-sampled densities, enabling a balance between detail preservation and smoothness in rendering. Additionally, a silhouette loss is introduced to reinforce alignment, particularly in complex regions like clothing edges and facial contours. Our approach reduces rendering artifacts compared to state-of-the-art methods, though with a slight trade-off in cloth detail sharpness, resulting in visually coherent human renderings validated through extensive experiments.
Overview
The framework synthesizes photorealistic renderings of dynamic humans in arbitrary poses by integrating multiple components. The input consists of an image sequence, SMPL body pose parameters (J, Ω), and camera parameters. The Pose Correction Module refines SMPL parameters to align observed and canonical spaces. The Motion Field Module decomposes motion into skeletal and non-rigid deformations, outputting the corrected position ∆(x). The Ray Regressor predicts the canonical density σr and color c for each point in the canonical space. Simultaneously, the Triplane Density MLP generates SMPL-aligned density values σt using spatially-aware Triplane features. Finally, the Adaptive Blending Module combines σr and σt using a learnable blending parameter, ensuring robust density estimation for volume rendering. The output is a photorealistic rendering of the human subject, free from artifacts and inconsistencies.
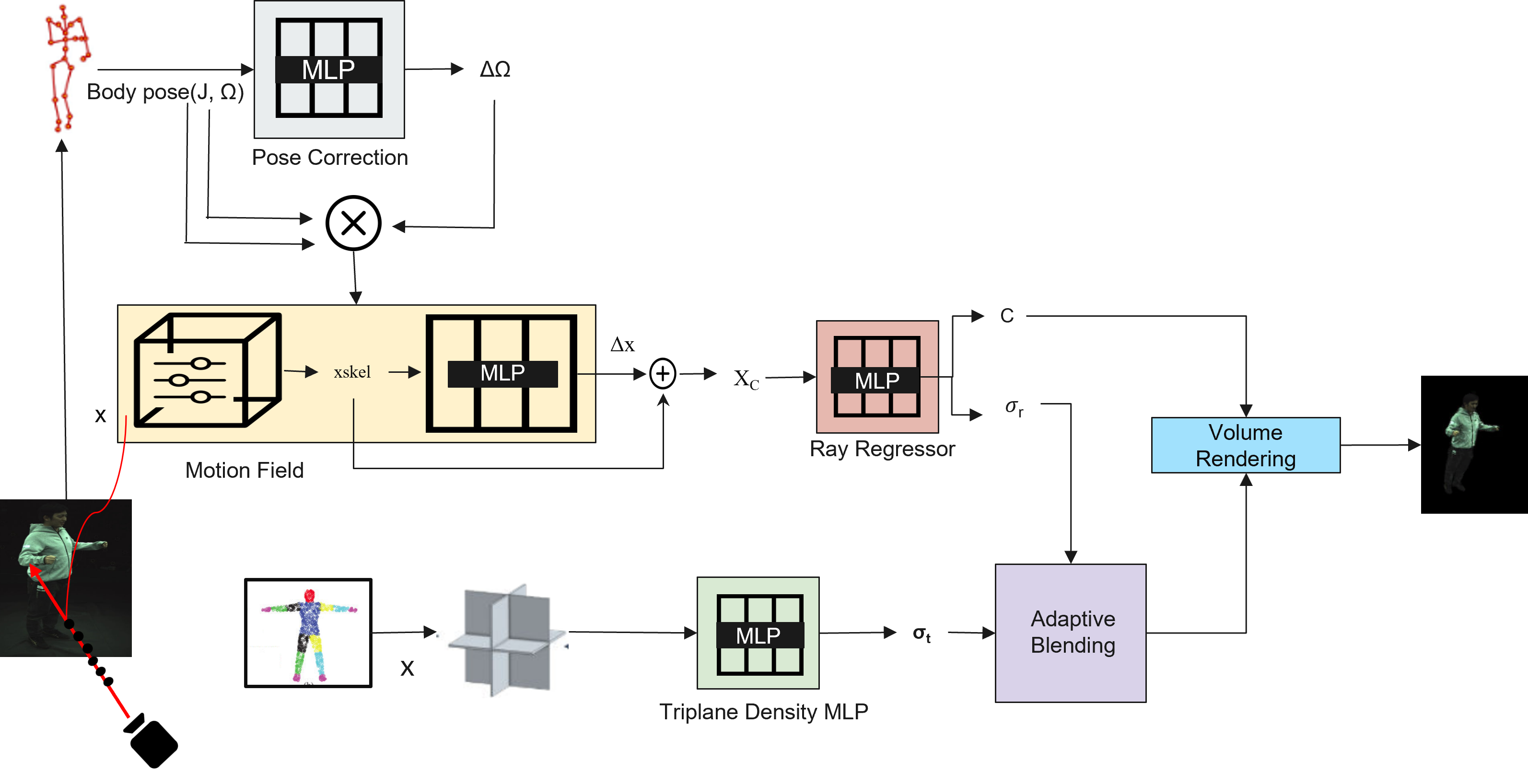
TE-NeRF overview: Triplane-enhanced representation and adaptive density blending
Quantitative Results
Quantitative comparison of individual subjects from the ZJU-MoCap dataset. LPIPS* = LPIPS × 103. The best metric values are highlighted in green and the second-best in orange.
| Method | Subject 377 | Subject 386 | Subject 387 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR ↑ | SSIM ↑ | LPIPS* ↓ | PSNR ↑ | SSIM ↑ | LPIPS* ↓ | PSNR ↑ | SSIM ↑ | LPIPS* ↓ | |
| Neural Body | 29.11 | 0.9674 | 40.95 | 30.54 | 0.9678 | 46.43 | 27.00 | 0.9518 | 59.47 |
| HumanNeRF | 30.41 | 0.9743 | 24.06 | 33.20 | 0.9752 | 28.99 | 28.18 | 0.9632 | 35.58 |
| TE-NeRF | 29.79 | 0.9656 | 29.41 | 32.73 | 0.9605 | 36.30 | 27.86 | 0.9596 | 39.87 |
| Method | Subject 392 | Subject 393 | Subject 394 | ||||||
| PSNR ↑ | SSIM ↑ | LPIPS* ↓ | PSNR ↑ | SSIM ↑ | LPIPS* ↓ | PSNR ↑ | SSIM ↑ | LPIPS* ↓ | |
| Neural Body | 30.10 | 0.9642 | 53.27 | 28.61 | 0.9590 | 59.05 | 29.10 | 0.9593 | 54.55 |
| HumanNeRF | 31.04 | 0.9705 | 32.12 | 28.31 | 0.9603 | 36.72 | 30.31 | 0.9642 | 32.89 |
| TE-NeRF | 30.23 | 0.9540 | 41.54 | 26.66 | 0.9284 | 65.16 | 29.68 | 0.9476 | 41.22 |
Qualitative Results
Qualitative comparisons illustrate TE-NeRF's improvements in reducing rendering artifacts while maintaining coherent surface geometry. The image below shows representative results: our Triplane-anchored density blending suppresses spurious background artifacts and improves silhouette alignment, particularly around clothing edges and facial contours. There is a small trade-off in cloth-detail sharpness in some cases, but overall visual coherence and artifact reduction are markedly improved. Refer to the figure for side-by-side examples and annotations.

Qualitative comparison: artifact reduction and silhouette alignment
Poster
BibTeX
@inproceedings{mubashshira2025tenerf,
title={TE-NeRF: Triplane-Enhanced Neural Radiance Field for Artifact-Free Human Rendering},
author={Mubashshira, Sadia and Desai, Kevin},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops},
year={2025}
}